8. IO 流
8.1 IO 流概述
- 什么是 IO 流?
- IO 流指的是:程序中数据的流动。数据可以从内存流动到硬盘,也可以从硬盘流动到内存。
- Java 中 IO 流最基本的作用是:完成文件的读和写。
- IO 流的分类?
(1)根据数据流向分为:输入和输出是相对于内存而言的。
- 输入流:从硬盘(read)到内存。(输入又叫做读:read)
- 输出流:从内存(write)到硬盘。(输出又叫做写:write)
(2)根据读写数据形式分为:
- 字节流:一次读取一个字节。适合读取非文本数据。例如图片、声音、视频等文件。(当然字节流是万能的。什么都可以读和写。)
- 字符流:一次读取一个字符。只适合读取普通文本。不适合读取二进制文件。因为字符流统一使用 Unicode 编码,可以避免出现编码混乱的问题。
注意:Java 的所有 IO 流中凡是以 Stream 结尾的都是字节流。凡是以 Reader 和 Writer 结尾的都是字符流。
(3)根据流在 IO 操作中的作用和实现方式来分类:
- 节点流:节点流负责数据源和数据目的地的连接,是 IO 中最基本的组成部分。
- 处理流:处理流对节点流进行装饰/包装,提供更多高级处理操作,方便用户进行数据处理。
Java 中已经将 IO 流实现了,在 java.io 包下,可以直接使用。
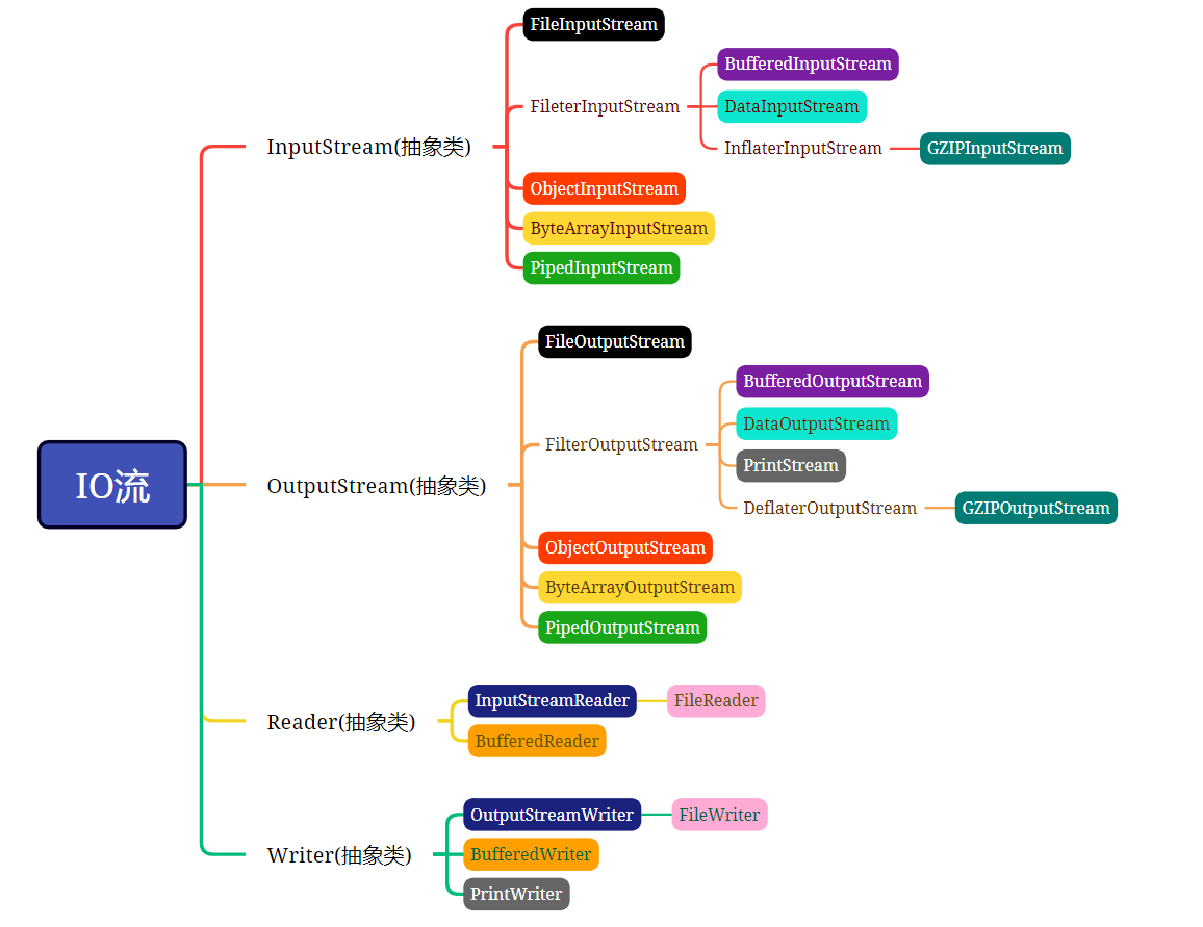
8.2 IO 流体系结构
InputStream:字节输入流OutputStream:字节输出流Reader:字符输入流Writer:字符输出流
以上 4 个流都是抽象类,是所有 IO 流的四大头领!所有的流都实现了 Closeable 接口,都有 close()方法,流用完要关闭。所有的输出流都实现了 Flushable 接口,都有 flush()方法,flush 方法的作用是,将缓存清空,全部写出。养成好习惯,以防数据丢失。
下图是常用的 IO 流:
8.3 FileInputStream
- 文件字节输入流,可以读取任何文件。
- 常用构造方法
FileInputStream(String name):创建一个文件字节输入流对象,参数是文件的路径
- 常用方法
int read(): 从文件读取一个字节(8 个二进制位),返回值读取到的字节本身,如果读不到任何数据返回-1int read(byte[] b): 一次读取多个字节,如果文件内容足够多,则一次最多读取 b.length 个字节。返回值是读取到字节总数。如果没有读取到任何数据,则返回 -1int read(byte[] b, int off, int len): 读到数据后向 byte 数组中存放时,从 off 开始存放,最多读取 len 个字节。读取不到任何数据则返回 -1long skip(long n): 跳过 n 个字节int available(): 返回流中剩余的估计字节数量。void close(): 关闭流。
- 使用 FileInputStream 读取的文件中有中文时,有可能读取到中文某个汉字的一半,在将 byte[]数组转换为 String 时可能出现乱码问题,因此 FileInputStream 不太适合读取纯文本。
FileInputStream file = null;
try {
file = new FileInputStream("/Users/user/Documents...");
byte[] bytes = new byte[4];
int readCount = 0;
while((readCount = file.read(bytes)) != -1) {
String s = new String(bytes,0,readCount);
System.out.println(s);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (file != null) {
try {
file.close();
} catch(IOException e) {
e.printStackTrace();
}
}
}8.4 FileOutputStream
- 文件字节输出流。
- 常用构造方法:
FileOutputStream(String name)创建输出流,先将文件清空,再不断写入。FileOutputStream(String name, boolean append)创建输出流,在原文件最后面以追加形式不断写入。
- 常用方法:
write(int b): 写一个字节void write(byte[] b): 将字节数组中所有数据全部写出void write(byte[] b, int off, int len): 将字节数组的一部分写出void close(): 关闭流void flush(): 刷新
- 使用 FileInputStream 和 FileOutputStream 完成文件的复制。
FileOutputStream out = null;
FileInputStream in = null;
try {
in = new FileInputStream("file1");
out = new FileOutputStream("file2");
byte[] bytes = new byte[1024];
int readCount = 0;
while((readCount = in.read(bytes)) != -1) {
out.write(bytes,0,readCount);
}
out.flush();
} catch(IOException e) {
e.printStackTrace();
} finally {
if(in != null) {
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(out != null) {
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}try-with-resources
采用 try-with-resources 写法,当 try 中代码执行结束(正常结束/异常结束)之后就会调用 try()括号中对象的 close()方法来关闭资源,虽然表面上来看 try-with-resources 写法更加优雅,如果我们对 try-with-resources 语法代码进行反编译,可以看到里面仍然是 try-catch-finally 写法,所以说 try-with-resources 写法是一种语法糖写法。
try (FileInputStream in = new FileInputStream("");
FileOutputStream out = new FileOutputStream("")) {
byte[] bytes = new byte[1024];
int readCount = 0;
while ((readCount = in.read(bytes)) != -1) {
out.write(bytes, 0, readCount);
}
out.flush();
} catch (IOException e) {
e.printStackTrace();
}8.5 FileReader
- 文件字符输入流
- 常用的构造方法:
FileReader(String fileName)
- 常用的方法:
int read()int read(char[] cbuf)int read(char[] cbuf, int off, int len)long skip(long n)void close()
try(FileReader fileReader = new FileReader("");) {
char[] chars = new char[512];
int readCount = 0;
while((readCount = fileReader.read(chars)) != -1) {
System.out.println(new String(chars,0,readCount));
}
} catch (IOException e) {
e.printStackTrace();
}8.6 FileWriter
- 文件字符输出流
- 常用的构造方法:
FileWriter(String fileName)FileWriter(String fileName, boolean append)
- 常用的方法:
void write(char[] cbuf)void write(char[] cbuf, int off, int len)void write(String str)void write(String str, int off, int len)void flush()void close()Writer append(CharSequence csq, int start, int end)
- 使用 FileReader 和 FileWriter 拷贝普通文本文件
try(FileReader reader = new FileReader("D:\\...\\file");
FileWriter writer = new FileWriter("D:\\...\\fileCopy")) {
char[] chars = new char[1024];
int readCount = 0;
while ((readCount = reader.read(chars)) != -1) {
writer.write(chars,0,readCount);
}
} catch(FileNotFoundException e) {
throw new RuntimeException(e);
} catch (IOException e) {
e.printStackTrace();
}补充知识:获取文件路径
- 绝对路径:
E:\\AA\\BB\\fileE:/AA/BB/file
相对路径: 在 idea 的工具中,默认的根路径是当前项目的根目录,即
currentProject/.../file获取当前类路径(从类路径中加载资源):
String path = Thread.currentThread()
.getContextClassLoader()
.getResource("file")
.getPath();
System.out.println(path);8.7 缓冲流
BufferedInputStream、BufferedOutputStream: 适合读写非普通文本文件BufferedReader、BufferedWriter: 适合读写普通文本文件- 缓冲流的读写速度快,原理是:在内存中准备了一个缓存。读的时候从缓存中读。写的时候将缓存中的数据一次写出。都是在减少和磁盘的交互次数。
- 缓冲流都是处理流/包装流。FileInputStream/FileOutputStream 是节点流。
- 关闭流只需要关闭最外层的处理流即可,通过源码就可以看到,当关闭处理流时,底层节点流也会关闭。
- 输出效率是如何提高的?在缓冲区中先将字符数据存储起来,当缓冲区达到一定大小或者需要刷新缓冲区时,再将数据一次性输出到目标设备。
- 输入效率是如何提高的? read()方法从缓冲区中读取数据。当缓冲区中的数据不足时,它会自动从底层输入流中读取一定大小的数据,并将数据存储到缓冲区中。大部分情况下,我们调用 read()方法时,都是从缓冲区中读取,而不需要和硬盘交互。
- 可以编写拷贝的程序测试一下缓冲流的效率是否提高了!
- 缓冲流的特有方法(输入流):以下两个方法的作用是允许我们在读取数据流时回退到原来的位置(重复读取数据时用)
void mark(int readAheadLimit): 标记位置(在 Java21 版本中,参数无意义。低版本 JDK 中参数表示在标记处最多可以读取的字符数量,如果你读取的字符数超出的上限值,则调用 reset()方法时出现 IOException。)void reset(): 重新回到上一次标记的位置这两个方法有先后顺序:先 mark 再 reset,另外这两个方法不是在所有流中都能用。有些流中有这个方法,但是不能用。
BufferedInputStream bis = null;
try {
FileInputStream in =
new FileInputStream("/Users/user/.../file01");
bis = new BufferedInputStream(in);
// bis = new BufferedInputStream(new FileInputStream(""));
byte[] bytes = new byte[1024];
int readCount = 0;
while((readCount = bis.read(bytes))!= -1) {
System.out.println(new String(bytes,0,readCount));
}
} catch(IOException e) {
e.printStackTrace();
} finally {
if(bis != null) {
try {
bis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}8.8 转换流
InputStreamReader(主要解决读的乱码问题)
- InputStreamReader 为转换流,属于字符流。
- 作用是将文件中的字节转换为程序中的字符。转换过程是一个解码的过程。
- 常用的构造方法:
InputStreamReader(InputStream in, String charsetName)指定字符集InputStreamReader(InputStream in)采用平台默认字符集
- 乱码是如何产生的?文件的字符集和构造方法上指定的字符集不一致。
- FileReader 是 InputStreamReader 的子类。本质上以下代码是一样的:
//采用平台默认字符集
Reader reader = new InputStreamReader(new FileInputStream(“file.txt”));
//采用平台默认字符集
Reader reader = new FileReader(“file.txt”);因此 FileReader 的出现简化了代码的编写。 以下代码本质上也是一样的:
Reader reader =
new InputStreamReader(new FileInputStream("file.txt"), "GBK");
Reader reader =
new FileReader("e:/file1.txt", Charset.forName("GBK"));OutputStreamWriter(主要解决写的乱码问题)
- OutputStreamWriter 是转换流,属于字符流。
- 作用是将程序中的字符转换为文件中的字节。这个过程是一个编码的过程。
- 常用构造方法:
OutputStreamWriter(OutputStream out, String charsetName)使用指定的字符集OutputStreamWriter(OutputStream out)采用平台默认字符集
- 乱码是如何产生的?文件的字符集与程序中构造方法上的字符集不一致。
- FileWriter 是 OutputStreamWriter 的子类。以下代码本质上是一样的:
// 采用平台默认字符集
Writer writer =
new OutputStreamWriter(new FileOutputStream("file1.txt"));
// 采用平台默认字符集
Writer writer = new FileWriter("file1.txt");因此 FileWriter 的出现,简化了代码。 以下代码本质上也是一样的:
Writer writer =
new OutputStreamWriter(new FileOutputStream("file1.txt"), "GBK");
Writer writer =
new FileWriter("file1.txt", Charset.forName("GBK"));8.9 数据流
DataOutputStream/DataInputStream
- 这两个流都是包装流,读写数据专用的流。
- DataOutputStream 直接将程序中的数据写入文件,不需要转码,效率高。程序中是什么样子,原封不动的写出去。写完后,文件是打不开的。即使打开也是乱码,文件中直接存储的是二进制。
- 使用 DataOutputStream 写的文件,只能使用 DataInputStream 去读取。并且读取的顺序需要和写入的顺序一致,这样才能保证数据恢复原样。
- 构造方法:
DataInputStream(InputStream in)DataOutputStream(OutputStream out)
- 写的方法:
writeByte()、writeShort()、writeInt()、writeLong()、writeFloat()、writeDouble()、writeBoolean()、writeChar()、writeUTF(String)
- 读的方法:
readByte()、readShort()、readInt()、readLong()、readFloat()、readDouble()、readBoolean()、readChar()、readUTF()
8.10 对象流
ObjectOutputStream/ObjectInputStream
- 通过这两个流,可以完成对象的序列化和反序列化。
- 序列化(Serial):将 Java 对象转换为字节序列。(为了方便在网络中传输),使用 ObjectOutputStream 序列化。
- 反序列化(DeSerial):将字节序列转换为 Java 对象。使用 ObjectInputStream 进行反序列化。
- 参与序列化和反序列化的 java 对象必须实现一个标志性接口:
java.io.Serializable - 实现了 Serializable 接口的类,编译器会自动给该类添加序列化版本号的属性:serialVersionUID
- 在 java 中,是通过“类名 + 序列化版本号”来进行类的区分的。
- serialVersionUID 实际上是一种安全机制。在反序列化的时候,JVM 会去检查存储 Java 对象的文件中的 class 的序列化版本号是否和当前 Java 程序中的 class 的序列化版本号是否一致。如果一致则可以反序列化。如果不一致则报错。
- 如果一个类实现了 Serializable 接口,还是建议将序列化版本号固定死,建议显示的定义出来,原因是:类有可能在开发中升级(改动),升级后会重新编译,如果没有固定死,编译器会重新分配一个新的序列化版本号,导致之前序列化的对象无法反序列化。显示定义序列化版本号的语法:
private static final long serialVersionUID = XXL; - 为了保证显示定义的序列化版本号不会写错,建议使用
@java.io.Serial注解进行标注。并且使用它还可以帮助我们随机生成序列化版本号。 - 不参与序列化的属性需要使用瞬时关键字修饰:
transient
8.11 打印流
PrintStream
- 打印流(字节形式)
- 主要用在打印方面,提供便捷的打印方法和格式化输出。主要打印内容到文件或控制台。
- 常用方法:
print(Type x)println(Type x)
- 便捷在哪里?
- 直接输出各种数据类型
- 自动刷新和自动换行(println 方法)
- 支持字符串转义
- 自动编码(自动根据环境选择合适的编码方式)
- 格式化输出?调用
printf()方法。
%s表示字符串%d表示整数%f表示小数(%.2f 这个格式就代表保留两位小数的数字)%c表示字符
PrintWriter
- 打印流(字符形式)注意 PrintWriter 使用时需要手动调用 flush()方法进行刷新。
- 比 PrintStream 多一个构造方法,PrintStream 参数只能是 OutputStream 类型,但 PrintWriter 参数可以是 OutputStream,也可以是 Writer。
- 常用方法:
print(Type x)println(Type x)
- 同样,也可以支持格式化输出,调用 printf 方法。
8.12 标准输入流&标准输出流
标准输入流
- System.in 获取到的 InputStream 就是一个标准输入流。
- 标准输入流是用来接收用户在控制台上的输入的。(普通的输入流,是获得文件或网络中的数据)
- 标准输入流不需要关闭。(它是一个系统级的全局的流,JVM 负责最后的关闭。)
- 也可以使用 BufferedReader 对标准输入流进行包装。这样可以方便的接收用户在控制台上的输入。(这种方式太麻烦了,因此 JDK 中提供了更好用的 Scanner。)
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));String s = br.readLine();
- 当然,你也可以修改输入流的方向(System.setIn())。让其指向文件。
InputStream in = System.in;
byte[] bytes = new byte[1024];
int readCount = in.read(bytes);
for (int i = 0; i < readCount; i++) {
System.out.println(bytes[i]);
// 输入 abcd
// 输出 97 98 99 100 10 (10为换行符的ASCII码)
}标准输出流
- System.out 获取到的 PrintStream 就是一个标准输出流。
- 标准输出流是用来向控制台上输出的。(普通的输出流,是向文件和网络等输出的。)
- 标准输出流不需要关闭(它是一个系统级的全局的流,JVM 负责最后的关闭。)也不需要手动刷新。
- 当然,你也可以修改输出流的方向(System.setOut())。让其指向文件。
PrintStream out = System.out;
out.println("11122");
out.println(true);
out.println(12);
out.println(43.75);
// 修改输出流的方向
System.setOut(new PrintStream("file"));
System.out.println("22222");8.13 File 类 ✅
- File 类不是 IO 流,和 IO 的四个头领没有关系。因此通过 File 是无法读写文件。
- File 类是路径的抽象表示形式,这个路径可能是目录,也可能是文件。因此 File 代表了某个文件或某个目录。
- File 类常用的构造方法:
File(String pathname); - File 类的常用方法:
boolean createNewFile():创建一个新的空文件。如果文件已存在,则不执行任何操作。boolean delete(): 删除此抽象路径名表示的文件或目录。如果此路径名表示一个目录,则必须为空才能删除。boolean exists():检查此抽象路径名表示的文件或目录是否存在。String getAbsolutePath():返回此抽象路径名的绝对路径名字符串。String getName():返回由此抽象路径名表示的文件或目录的名称。String getParent():返回此抽象路径名的父路径名字符串,如果此路径名没有指定父目录,则返回 null。boolean isAbsolute():测试此抽象路径名是否为绝对路径名。boolean isDirectory():测试此抽象路径名表示的是否是一个目录。boolean isFile():测试此抽象路径名表示的是否是一个标准文件。boolean isHidden():测试此抽象路径名表示的文件是否是一个隐藏文件。long lastModified():返回此抽象路径名表示的文件最后一次被修改的时间。long length():返回由此抽象路径名表示的文件的长度。File[] listFiles():返回一个抽象路径名数组,这些路径名表示此抽象路径名表示的目录中的文件和目录。File[] listFiles(FilenameFilter filter):返回一个抽象路径名数组,这些路径名表示此抽象路径名表示的目录中满足指定过滤器的文件和目录。boolean mkdir():创建由此抽象路径名命名的单级目录。boolean mkdirs():创建由此抽象路径名命名的目录,包括创建必需但不存在的父目录。boolean renameTo(File dest):重命名此抽象路径名表示的文件。boolean setReadOnly():将此抽象路径名标记为只读。boolean setWritable(boolean writable):设置此抽象路径名的可写性。如果参数为 true,则确保文件是可写的;如果为 false,则在文件系统中尝试使文件只读。
编写程序要求可以完成目录的拷贝。
目录(文件夹)拷贝
public class CopyDir {
public static void main(String[] args) {
File src = new File("D:\\...\\src");
File dest = new File("D:\\...\\javatest07");
copy(src, dest);
}
private static void copy(File src, File dest) {
if (src.isFile()) {
try (FileInputStream in = new FileInputStream(src);
FileOutputStream out =
new FileOutputStream(dest.getAbsolutePath() + src.getAbsolutePath().substring(2));) {
byte[] bytes = new byte[1024 * 1024];
int readCount = 0;
while ((readCount = in.read(bytes)) != -1) {
out.write(bytes, 0, readCount);
}
out.flush();
} catch (Exception e) {
e.printStackTrace();
}
return;
}
File newDir =
new File(dest.getAbsolutePath() + src.getAbsolutePath().substring(2));
if (!newDir.exists()) {
newDir.mkdirs();
}
File[] files = src.listFiles();
for (File file : files) {
System.out.println(file.getAbsoluteFile());
copy(file, dest);
}
}
}8.14 读取属性配置文件
Properties + IO
- xxx.properties 文件称为属性配置文件。
- 属性配置文件可以配置一些简单的信息,例如连接数据库的信息通常配置到属性文件中。这样可以做到在不修改 java 代码的前提下,切换数据库。
- 属性配置文件的格式:
key1=value1key2=value2key3=value3
注意:使用 # 进行注释。key 不能重复,key 重复则 value 覆盖。key 和 value 之间用等号分割。等号两边不要有空格。
- Java 中如何读取属性配置文件?
- 当然,也可以使用 Java 中的工具类快速获取配置信息:ResourceBundle
- 这种方式要求文件必须是 xxx.properties
- 属性配置文件必须放在类路径当中
try (FileReader reader = new FileReader("D:\\...\\jdbc.properties");) {
Properties pro = new Properties();
pro.load(reader);
Enumeration<?> names = pro.propertyNames();
while (names.hasMoreElements()) {
String name = (String) names.nextElement();
String value = pro.getProperty(name);
System.out.println(name + "---" + value);
}
} catch (Exception e) {
e.printStackTrace();
}8.15 装饰器设计模式
装饰器设计模式(Decorator Pattern)
- 思考:如何扩展一个类的功能?继承确实也可以扩展对象的功能,但是接口下的实现类很多,每一个子类都需要提供一个子类。就需要编写大量的子类来重写父类的方法。会导致子类数量至少翻倍,会导致类爆炸问题。
- 装饰器设计模式是 GoF23 种设计模式之一,属于结构型设计模式。(结构型设计模式通常处理对象和类之间的关系,使程序员能够更好地组织代码并更好地利用现有代码。)
- IO 流中使用了大量的装饰器设计模式。
- 装饰器设计模式作用:装饰器模式可以做到在不修改原有代码的基础之上,完成功能扩展,符合 OCP 原则。并且避免了使用继承带来的类爆炸问题。
- 装饰器设计模式中涉及到的角色包括:
- 抽象的装饰者
- 具体的装饰者 1、具体的装饰者 2
- 被装饰者
- 装饰者和被装饰者的公共接口/公共抽象类
8.16 压缩和解压缩流
GZIPOutputStream(压缩)
- 使用 GZIPOutputStream 可以将文件制作为压缩文件,压缩文件的格式为 .gz 格式。
- 核心代码:
// 被压缩的文件:test.txt
FileInputStream fis = new FileInputStream("d:/test.txt");
// 压缩后的文件
GZIPOutputStream gzos =
new GZIPOutputStream(new FileOutputStream("d:/test.txt.gz"))
// 接下来就是边读边写:
int length;
while ((length = fis.read(buffer)) > 0) {
gzos.write(buffer, 0, length);
}
// 在压缩完所有数据之后调用finish()方法,
// 以确保所有未压缩的数据都被刷新到输出流中,
// 并生成必要的 Gzip 结束标记,标志着压缩数据的结束。
gzos.finish();- 注意(补充):实际上所有的输出流中,只有带有缓冲区的流才需要手动刷新,节点流是不需要手动刷新的,节点流在关闭的时候会自动刷新。
GZIPInputStream(解压缩)
- 使用 GZIPInputStream 可以将 .gz 格式的压缩文件解压。
- 核心代码:
GZIPInputStream gzip =
new GZIPInputStream(new FileInputStream("d:/test.txt.gz"));
FileOutputStream out = new FileOutputStream("d:/test.txt");
byte[] bytes = new byte[1024];
int readCount = 0;
while((readCount = gzip.read(bytes)) != -1){
out.write(bytes, 0, readCount);
}8.17 字节数组流
字节数组流(内存流)
ByteArrayInputStream和ByteArrayOutputStream都是内存操作流,不需要打开和关闭文件等操作。这些流是非常常用的,可以将它们看作开发中的常用工具,能够方便地读写字节数组、图像数据等内存中的数据。ByteArrayInputStream和ByteArrayOutputStream都是节点流。ByteArrayOutputStream,将数据写入到内存中的字节数组当中。ByteArrayInputStream,读取内存中某个字节数组中的数据。
8.18 对象克隆
- 除了我们之前所讲的深克隆方式(之前的深克隆是重写 clone()方法)。使用字节数组流也可以完成对象的深克隆。
- 原理是:将要克隆的 Java 对象写到内存中的字节数组中,再从内存中的字节数组中读取对象,读取到的对象就是一个深克隆。
- 目前为止,对象拷贝方式:
- 调用 Object 的 clone 方法,默认是浅克隆,需要深克隆的话,就需要重写 clone 方法。
- 可以通过序列化和反序列化完成对象的克隆。
- 也可以通过 ByteArrayInputStream 和 ByteArrayOutputStream 完成深克隆。
Address addr = new Address("beijing", "dong");
User user = new User("Tom", 18, addr);
// 将对象写入到byte数组中
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(user);
oos.flush();
// 从byte数组中读取对象
ByteArrayInputStream bais =
new ByteArrayInputStream(baos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bais);
User newUser = (User) ois.readObject();
System.out.println(newUser);